4A. Title Generation - Developing the Model - Embeddings
This post looks at developing our initial models to include state of the art features to improve results.
To recap:
- We have two models: the Ludwig model and the Chollet/Brownlee model.
- Performance so far has been fairly poor.
- Each model had slightly different characteristics - the Ludwig model produced better formed output but seemed to simply memorise and repeat titles, the Chollet/Brownlee model had a lower loss and appeared to memorise less but produced more nonsensical outputs.
In our last post we identified a number of ways to improve our models:
- Use GloVe encodings and a shared embedding layer.
- Add attention.
- Add pointers / skip connections between our input and our output.
- Use a coverage measure.
- Use different word forms such as lemmas or stems.
- Use a GAN-style discriminator on the output.
- Improve our sampling by employing beam search.
Over the next set of posts, we will look at the first two of these in detail. This post starts with using pre-trained embedding weights and an embedding layer that is shared across the encoder and decoder input.
# Imports
import numpy as np
import os
Using Pre-trained Shared Embeddings
Here we will look at two complementary modifications to our model:
- We can speed-up our training by using a set of pre-trained embedding weights; and
- As the encoder and decoder both take words with a similar vocabulary as input, we can share a single set of weights between the encoder and decoder.
Pre-trained Embedding Weights
There are several different ways to generate and use a set of pre-trained word embeddings. Two very common approaches are to use either pretrained GloVe or Word2Vec embeddings. Anecdotally, for small toy projects, both have similar characteristics. The GloVe vectors are the easiest to download and use, so we'll start with those.
As a start, I recommend using the 100 dimension vectors generated from a crawl of 6 billion words. This can be downloaded as a text file from here. This is to be placed in a /glove directory.
Then we follow the steps from Ludwig's example to generate our embedding matrix.
The code below reads the entries in the text file and generates a dictionary indexed by a word with a numpy array containing the embedding vector as an entry.
GLOVE_DIR = "glove/"
embeddings_index = {}
# For Python 3 tweaked to add 'rb'
f = open(os.path.join(GLOVE_DIR, 'glove.6B.100d.txt'), 'rb')
for line in f:
values = line.split()
# Tweaked to decode the binary text values
word = values[0].decode('utf-8')
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
len(embeddings_index)
400000
list(embeddings_index.keys())[0:10]
['irati',
'fotiou',
'8-year',
'usagi',
'autobianchi',
'eldercare',
'puraskar',
'dench',
'ventrally',
'amsc']
As we can see there are 400,000 words. Some of which are fairly arcane (note "eldercare", which is a US-centric term). Below is the 100d word embedding vector for "the".
embeddings_index.get('the')
array([-0.038194, -0.24487 , 0.72812 , -0.39961 , 0.083172, 0.043953,
-0.39141 , 0.3344 , -0.57545 , 0.087459, 0.28787 , -0.06731 ,
0.30906 , -0.26384 , -0.13231 , -0.20757 , 0.33395 , -0.33848 ,
-0.31743 , -0.48336 , 0.1464 , -0.37304 , 0.34577 , 0.052041,
0.44946 , -0.46971 , 0.02628 , -0.54155 , -0.15518 , -0.14107 ,
-0.039722, 0.28277 , 0.14393 , 0.23464 , -0.31021 , 0.086173,
0.20397 , 0.52624 , 0.17164 , -0.082378, -0.71787 , -0.41531 ,
0.20335 , -0.12763 , 0.41367 , 0.55187 , 0.57908 , -0.33477 ,
-0.36559 , -0.54857 , -0.062892, 0.26584 , 0.30205 , 0.99775 ,
-0.80481 , -3.0243 , 0.01254 , -0.36942 , 2.2167 , 0.72201 ,
-0.24978 , 0.92136 , 0.034514, 0.46745 , 1.1079 , -0.19358 ,
-0.074575, 0.23353 , -0.052062, -0.22044 , 0.057162, -0.15806 ,
-0.30798 , -0.41625 , 0.37972 , 0.15006 , -0.53212 , -0.2055 ,
-1.2526 , 0.071624, 0.70565 , 0.49744 , -0.42063 , 0.26148 ,
-1.538 , -0.30223 , -0.073438, -0.28312 , 0.37104 , -0.25217 ,
0.016215, -0.017099, -0.38984 , 0.87424 , -0.72569 , -0.51058 ,
-0.52028 , -0.1459 , 0.8278 , 0.27062 ], dtype=float32)
Loading and Tokenizing Data
Initially we load our data as before. Our tokenizing routine changes a little, as we will use a common tokenizer on both the claim text and title. This allows us to use a shared embedding layer.
# Set parameters
num_decoder_tokens = 2500 # This is our output title vocabulary
num_encoder_tokens = 2500 # This is our input claim vocabulary
encoder_seq_length = 300 # This is our limit for our input claim length
decoder_seq_length = 22 # This is our limit for our output title length - 20 + 2 for start/stop
import pickle
import os
PIK = "claim_and_title.data"
if not os.path.isfile(PIK):
# Download file
!wget https://benhoyle.github.io/notebooks/title_generation/claim_and_title.data
with open(PIK, "rb") as f:
print("Loading data")
data = pickle.load(f)
print("{0} samples loaded".format(len(data)))
print("\n\nAdding start and stop tokens to output")
data = [(c, "startseq {0} stopseq".format(t)) for c, t in data]
print("\n\nAn example title:", data[0][1])
print("----")
print("An example claim:", data[0][0])
Loading data
30000 samples loaded
Adding start and stop tokens to output
An example title: startseq System and method for session restoration at geo-redundant gateways stopseq
----
An example claim:
1. A method for managing a backup service gateway (SGW) associated with a primary SGW, the method comprising:
periodically receiving from the primary SGW at least a portion of corresponding UE session state information, the received portion of session state information being sufficient to enable the backup SGW to indicate to an inquiring management entity that UEs having an active session supported by the primary SGW are in a live state; and
in response to a failure of the primary SGW, the backup SGW assuming management of IP addresses and paths associated with said primary SGW and transmitting a Downlink Data Notification (DDN) toward a Mobility Management Entity (MME) for each of said UEs having an active session supported by the failed primary SGW to detach from the network and reattach to the network, wherein each DDN causes the MME to send a detach request with a reattach request code to the respective UE.
from keras.preprocessing import text
t_joint = text.Tokenizer(
num_words=num_encoder_tokens,
lower=True,
char_level=False,
oov_token="<UNK>"
)
X_texts = [d[0] for d in data]
Y_texts = [d[1] for d in data]
total_texts = X_texts + Y_texts
t_joint.fit_on_texts(total_texts)
/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
Using TensorFlow backend.
list(t_joint.word_index.keys())[0:10]
['remapper',
'inactive',
'imposes',
'overestimates',
'roman',
'mitigating',
"location's",
'56a',
'buckle',
'billable']
X_seqs = t_joint.texts_to_sequences(X_texts)
Y_seqs = t_joint.texts_to_sequences(Y_texts)
print("Our input sequences (claims) have a max integer value of {0}".format(max([max(x) for x in X_seqs])))
print("Our output sequences (titles) have a max integer value of {0}".format(max([max(y) for y in Y_seqs])))
Our input sequences (claims) have a max integer value of 2499
Our output sequences (titles) have a vocabulary of 2499 words
vocab_size = max([max(x + y) for x, y in zip(X_seqs, Y_seqs)]) + 1
vocab_size
2500
filtered_seqs = [(x, y) for x,y in zip(X_seqs, Y_seqs) if len(x) <= encoder_seq_length and len(y) <= decoder_seq_length]
X_seqs = [x for x, _ in filtered_seqs]
Y_seqs = [y for _, y in filtered_seqs]
X_length = [len(x) for x in X_seqs]
max_length = max(X_length)
print("Our longest input sequence is {0} tokens long.".format(max_length))
Y_length = [len(y) for y in Y_seqs]
max_length = max(Y_length)
print("Our longest output sequence is {0} tokens long.".format(max_length))
Our longest input sequence is 300 tokens long.
Our longest output sequence is 22 tokens long.
Building the Word Embedding Matrix
Now we have a dictionary of numpy arrays indexed by word strings and a dictionary of ranked words from the Keras tokenizer we can build the matrix to use as the initial weights for our shared embedding layer.
We need to filter the tokenizer dictionary to remove all words that are ranked less than our number of alloted tokens for the encoder and decoder inputs (e.g. all with ranks less than the vocabulary size of 2500).
We then iterate through our words from the tokenizer dictionary and link the word index integers with the embedding vectors.
word_embedding_size = 100 # As we are using the Glove 100d data
print('Found {0} word vectors.'.format(len(embeddings_index)))
embedding_matrix = np.zeros((vocab_size, word_embedding_size))
# Filter our vocab to only the used items
words = [(w, i) for w, i in t_joint.word_index.items() if int(i) < vocab_size]
# This is from https://machinelearningmastery.com/use-word-embedding-layers-deep-learning-keras/
for word, i in words:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Found 400000 word vectors.
The resultant matrix should be of shape : vocabulary size by GloVe dimensions = 2500 x 100.
embedding_matrix.shape
(2500, 100)
Finish Preparing Data
Now we just finish preparing the data by padding as before.
print(X_texts[0], X_seqs[0])
print(Y_texts[0], Y_seqs[0])
1. A method for managing a backup service gateway (SGW) associated with a primary SGW, the method comprising:
periodically receiving from the primary SGW at least a portion of corresponding UE session state information, the received portion of session state information being sufficient to enable the backup SGW to indicate to an inquiring management entity that UEs having an active session supported by the primary SGW are in a live state; and
in response to a failure of the primary SGW, the backup SGW assuming management of IP addresses and paths associated with said primary SGW and transmitting a Downlink Data Notification (DDN) toward a Mobility Management Entity (MME) for each of said UEs having an active session supported by the failed primary SGW to detach from the network and reattach to the network, wherein each DDN causes the MME to send a detach request with a reattach request code to the respective UE.
[31, 2, 29, 8, 448, 2, 552, 91, 1047, 42, 19, 2, 397, 1, 29, 26, 1959, 51, 20, 1, 397, 14, 25, 2, 74, 3, 61, 352, 109, 28, 1, 96, 74, 3, 352, 109, 28, 58, 2214, 4, 782, 1, 552, 4, 1008, 4, 11, 142, 261, 24, 69, 11, 500, 352, 1510, 15, 1, 397, 60, 6, 2, 1672, 109, 5, 6, 75, 4, 2, 888, 3, 1, 397, 1, 552, 142, 3, 603, 685, 5, 937, 42, 19, 16, 397, 5, 252, 2, 9, 494, 1653, 2, 142, 261, 8, 32, 3, 16, 69, 11, 500, 352, 1510, 15, 1, 2193, 397, 4, 20, 1, 53, 5, 4, 1, 53, 18, 32, 957, 1, 4, 742, 2, 65, 19, 2, 65, 97, 4, 1, 118]
startseq System and method for session restoration at geo-redundant gateways stopseq [34, 30, 5, 29, 8, 352, 14, 1836, 35]
# Pad the data
from keras.preprocessing.sequence import pad_sequences
X = pad_sequences(X_seqs, maxlen=encoder_seq_length)
Y = pad_sequences(Y_seqs, maxlen=decoder_seq_length, padding='post')
print("Our X data has shape {0} and our Y data has shape {1}".format(X.shape, Y.shape))
Our X data has shape (25632, 300) and our Y data has shape (25632, 22)
Y[0]
array([ 34, 30, 5, 29, 8, 352, 14, 1836, 35, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
dtype=int32)
Adapting the Ludwig Model
We will now adapt the Ludwig model used in the previous post to use a shared embedding layer and the pre-trained GloVe vectors.
This is fairly simple - we just define an embedding layer and initialise it with the generated embedding matrix. We then specify that it is to be used on both the encoder and decoder inputs.
# imports
from keras.models import Model
from keras.layers import Input, LSTM, Dense, Embedding
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
%matplotlib inline
from keras.layers import concatenate
y_vocab_len = num_decoder_tokens # This is our output title vocabulary
X_vocab_len = num_encoder_tokens # This is our input claim vocabulary
X_max_len = encoder_seq_length # This is our limit for our input claim length
y_max_len = decoder_seq_length # This is our limit for our output title length - 20 + 2 for start/stop
# source text input model
inputs1 = Input(shape=(X_max_len,))
#am1 = Embedding(X_vocab_len, 128)(inputs1)
Shared_Embedding = Embedding(
output_dim=word_embedding_size,
input_dim=vocab_size,
weights=[embedding_matrix]
)
am1 = Shared_Embedding(inputs1)
am2 = LSTM(128)(am1)
# summary input model
inputs2 = Input(shape=(y_max_len,))
sm1 = Shared_Embedding(inputs2)
sm2 = LSTM(128)(sm1)
# decoder output model
decoder1 = concatenate([am2, sm2])
outputs = Dense(y_vocab_len, activation='softmax')(decoder1)
# tie it together [article, summary] [word]
model = Model(inputs=[inputs1, inputs2], outputs=outputs)
model.compile(loss='categorical_crossentropy', optimizer='adam')
model.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_7 (InputLayer) (None, 300) 0
__________________________________________________________________________________________________
input_8 (InputLayer) (None, 22) 0
__________________________________________________________________________________________________
embedding_3 (Embedding) (None, 2500, 100) 250000 input_7[0][0]
input_8[0][0]
__________________________________________________________________________________________________
lstm_5 (LSTM) (None, 128) 117248 embedding_3[0][0]
__________________________________________________________________________________________________
lstm_6 (LSTM) (None, 128) 117248 embedding_3[1][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 256) 0 lstm_5[0][0]
lstm_6[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 2500) 642500 concatenate_2[0][0]
==================================================================================================
Total params: 1,126,996
Trainable params: 1,126,996
Non-trainable params: 0
__________________________________________________________________________________________________
Now we see that the embedding is shared by both LSTMs.
We can now build our model in pretty much the same way as before...
# We need to split into train and test data
from sklearn.model_selection import train_test_split
# seed for reproducing same results
seed = 9
np.random.seed(seed)
# split the data into training (80%) and testing (20%)
(X_train, X_test, Y_train, Y_test) = train_test_split(X, Y, test_size=0.2, random_state=seed)
Y[0]
array([ 34, 30, 5, 29, 8, 352, 14, 1836, 35, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
dtype=int32)
One small bug we had to fix is that we can now no longer hard-code the integer indexes for our start and stop control tokens. We thus use the word_index dictionary to look up the integer based on the text.
def generate_set(X, Y, i_end, i):
""" Generate the data for training/validation from X and Y.
i_end is the end of the set, i is the start."""
set_size = 0
limit_list = list()
for sent in Y[i:i_end]:
# Edited below to use integer value of EOS symbol
limit = np.where(sent==t_joint.word_index["stopseq"])[0][0] # the position of the symbol EOS
set_size += limit + 1
limit_list.append(limit)
# We need to change this bit to set our array size based on the limit values
# Generate blank arrays for the set
I_1 = np.zeros((set_size, X_max_len))
I_2 = np.zeros((set_size, y_max_len))
# This below is a big array
Y_set = np.zeros((set_size, y_vocab_len))
count = 0
# Now we want to create, for each sample, a set of examples for each word in the title
# Have we just been training on 0 to 100?!?!
for l in range(0, (i_end - i)):
# for each X and y in set of NB_SET
# We need to build the input for the second encoder for the next word in y
# I.e. for word 3 in the title the input2 consists of words 1 and 2 (using teacher forcing)
# Get length of current title - i.e. where the integer = 2 = stopseq
limit = limit_list[l]
# We only need to create examples up to the length of the title
for m in range(1, limit+1):
# Generate our one-hot y out
one_hot_out = np.zeros((1, y_vocab_len))
# This builds our one-hot generation into our training loop
# The l and m respectively iterate through the samples and the output sequence elements
one_hot_out[0, Y[l+i][m]] = 1
# Create a blank row/array for a partial input for our summary model - this is fed into the decoder
# It is of the same size as our title
partial_input = np.zeros((1, y_max_len))
# Don't we also need to set partial input [0] to startseq as well? - no that's taken care of
# by m starting at one but our range below starting at 0
# Because we are zero padding add words up to m to end - DOES THIS STILL WORK IF WE ZERO PAD
# AT THE END? - Yes but we just feed the words with zeros first?
# What happens if we change this to 0:m?! - if we have [1, 2, 3, 4] this will generate
# [0,0,0,1], [0,0,1,2], [0,1, 2, 3]
# Our zero padding is at the end though so our seqs looks like [1,2,3,0,0,0],
# But I know you want the data need the end of the input seq to prevent forgetting
partial_input[0, -m:] = Y[l+i][0:m]
# This fills in each sample of the training data, i.e. count increments up to set size
I_1[count, :] = X[l+i]
I_2[count, :] = partial_input
Y_set[count, :] = one_hot_out
count += 1
# Shuffle the I_1, I_2 and Y_set vectors for better training - trick from RL
# - see here - np.take(X,np.random.permutation(X.shape[0]),axis=0,out=X);
indices = np.random.permutation(I_1.shape[0])
np.take(I_1, indices, axis=0, out=I_1)
np.take(I_2, indices, axis=0, out=I_2)
np.take(Y_set, indices, axis=0, out=Y_set)
return I_1, I_2, Y_set
# Basing training in sets code on here - https://github.com/ChunML/seq2seq/blob/master/seq2seq.py
# Function to look for saved weights file
def find_checkpoint_file(folder):
checkpoint_file = [f for f in os.listdir(folder) if 'v2_kerascheckpoint' in f]
if len(checkpoint_file) == 0:
return []
modified_time = [os.path.getmtime(f) for f in checkpoint_file]
return checkpoint_file[np.argmax(modified_time)]
# Finding trained weights of previous epoch if any
saved_weights = find_checkpoint_file('.')
k_start = 1
# If any trained weight was found, then load them into the model
if len(saved_weights) != 0:
print('[INFO] Saved weights found, loading...')
epoch = saved_weights[saved_weights.rfind('_')+1:saved_weights.rfind('.')]
model.load_weights(saved_weights)
k_start = int(epoch) + 1
# So instead of X we have [inputs1, inputs2] - this is where we need to fold in
# - https://github.com/oswaldoludwig/Seq2seq-Chatbot-for-Keras/blob/master/train_bot.py
# So we have inputs2 that build up - we have a set of inputs2 up to the length of inputs2
# We need to refactor some of the loops below as functions - we can then apply to test data to generate a validation set
[INFO] Saved weights found, loading...
import math
BATCH_SIZE = 32 # Depends on GPU - most values are around this 32-128
NB_EPOCH = 20
# Number of examples to group together in a set - 100 is fast / 1000 is too much on an 8-core i7 laptop
# I think 100 is good - 250 takes a time to generate the sets of test data
NB_SET = 250
i_end = 0
num_examples = len(X_train)
num_test = len(X_test)
# Initialise history of accuracy
train_loss = list()
val_loss = list()
# Continue from loaded epoch number or new epoch if not loaded
for k in range(k_start, NB_EPOCH+1):
# Shuffling the training data every epoch to avoid local minima
indices = np.arange(num_examples)
np.random.shuffle(indices)
X_train = X_train[indices]
Y_train = Y_train[indices]
indices = np.arange(num_test)
np.random.shuffle(indices)
X_test = X_test[indices]
Y_test = Y_test[indices]
# This for loop rotates through NB_SET samples at a time to avoid memory issues
# E.g. Training 100 sequences at a time
for i in range(0, num_examples, NB_SET):
if i + NB_SET >= num_examples:
i_end = num_examples
else:
i_end = i + NB_SET
# Generate a range for the test data
i_test = math.floor(i * (num_test/num_examples))
i_test_end = math.floor(i_end * (num_test/num_examples))
I_1_train, I_2_train, Y_set_train = generate_set(X_train, Y_train, i_end, i)
I_1_test, I_2_test, Y_set_test = generate_set(X_test, Y_test, i_test_end, i_test)
print('[INFO] Training model: epoch {} - {}/{} samples'.format(k, i, num_examples))
callback = model.fit(
[I_1_train, I_2_train],
Y_set_train,
validation_data=([I_1_test, I_2_test], Y_set_test),
batch_size=BATCH_SIZE,
epochs=1
)
train_loss += callback.history['loss']
val_loss += callback.history['val_loss']
# Get history and apppend new data to running set here
model.save_weights('v2_kerascheckpoint_epoch_{}.hdf5'.format(k))
[INFO] Training model: epoch 2 - 0/20505 samples
Train on 2534 samples, validate on 603 samples
Epoch 1/1
2534/2534 [==============================] - 22s 9ms/step - loss: 2.2101 - val_loss: 2.3826
[INFO] Training model: epoch 2 - 250/20505 samples
Train on 2464 samples, validate on 677 samples
Epoch 1/1
2464/2464 [==============================] - 22s 9ms/step - loss: 2.1098 - val_loss: 2.2632
[INFO] Training model: epoch 2 - 500/20505 samples
Train on 2404 samples, validate on 630 samples
Epoch 1/1
2404/2404 [==============================] - 21s 9ms/step - loss: 2.1046 - val_loss: 2.4288
....YADAYADAYADA...
[INFO] Training model: epoch 20 - 20000/20505 samples
Train on 2452 samples, validate on 662 samples
Epoch 1/1
2452/2452 [==============================] - 23s 9ms/step - loss: 1.1216 - val_loss: 2.6810
[INFO] Training model: epoch 20 - 20250/20505 samples
Train on 2506 samples, validate on 607 samples
Epoch 1/1
2506/2506 [==============================] - 24s 10ms/step - loss: 1.1131 - val_loss: 2.7156
[INFO] Training model: epoch 20 - 20500/20505 samples
Train on 39 samples, validate on 22 samples
Epoch 1/1
39/39 [==============================] - 1s 13ms/step - loss: 0.8315 - val_loss: 3.1535
So using the shared embedding appears to provide a small advantage in reducing our loss function. It also lowers the number of parameters for our model, which is a good thing as it reduces over-fitting and training time.
```python
# summarize history for accuracy
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Iteration')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
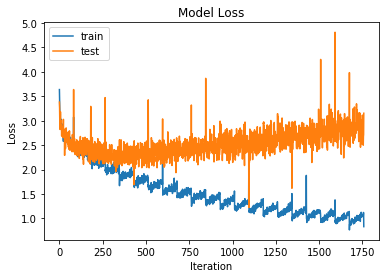
Now we've trained our model we need some code to test it. Again, this is pretty much as before but with some tweaks to use the word_index dictionaries to look up our control characters.
# Set up dictionary to translate indices to words
y_dictionary = dict(
(i, char) for char, i in t_joint.word_index.items()
)
x_dictionary = dict(
(i, char) for char, i in t_joint.word_index.items()
)
def seq2text(seq, dictionary):
text = ''
for k in seq:
k = k.astype(int)
# Adapted to take account of different control integers
if k not in [t_joint.word_index["stopseq"], t_joint.word_index["startseq"], 0] and k < (len(dictionary)-1):
w = dictionary[k]
text = text + w + ' '
return text
def greedy_decoder(X_seq):
# reformat input seq
input_seq = np.zeros((1, X_max_len))
input_seq[0, :] = X_seq
flag = 0
prob = 1
ans_partial = np.zeros((1, y_max_len))
# Add start token integer to end of ans_partial input - initially [0,0,...BOS]
ans_partial[0, -1] = t_joint.word_index["startseq"] # the index of the symbol BOS (begin of sentence)
for k in range(y_max_len - 1):
ye = model.predict([input_seq, ans_partial])
yel = ye[0,:]
p = np.max(yel)
mp = np.argmax(ye)
# It is this line that sets how our training data should be arranged - need to change both
# the line below shifts the existing ans_partial by 1 to the left - [0, 0, ..., BOS, 0]
ans_partial[0, 0:-1] = ans_partial[0, 1:]
# This then adds the newly decoded word onto the end of ans_partial
ans_partial[0, -1] = mp
if mp == t_joint.word_index["stopseq"]: # the index of the symbol EOS (end of sentence)
flag = 1
if flag == 0:
prob = prob * p
text = seq2text(ans_partial[0], y_dictionary)
return(text, prob)
# Testing
num_test_titles = len(X_test)
indices = np.arange(num_test_titles)
np.random.shuffle(indices)
X_test = X_test[indices]
Y_test = Y_test[indices]
for i in range(0, 5):
text, prob = greedy_decoder(X_test[i])
Y_test_text = seq2text(Y_test[i], y_dictionary)
claim_text = seq2text(X_test[i], x_dictionary)
print("Sample of claim text: {}\n".format(claim_text[0:200]))
print("Predicted title is: {} (with prob {}). \n Test title is: {} \n---".format(text, prob, Y_test_text))
Sample of claim text: 1 a method of memory page de in a computer system comprising a plurality of virtual machine partitions managed by a hypervisor wherein each virtual machine is assigned a different dedicated memory par
Predicted title is: virtual machine using virtual machine i o port (with prob 0.00024153314510963288).
Test title is: memory page de in a computer system that includes a plurality of virtual machines
---
Sample of claim text: 1 a method for operating a server comprising a processor for automatically generating an end user interface for working with the data within a relational database defined within a relational whose dat
Predicted title is: method and system for managing database objects in a database (with prob 0.0003222082082124349).
Test title is: system and method for generating automatic user interface for complex or large databases
---
Sample of claim text: 1 a method of processing user input in a three dimensional coordinate system comprising receiving a user input of an origin reset for the three dimensional coordinate system responsive to receiving th
Predicted title is: user interface based on user interaction surfaces type sources therein (with prob 0.0009777329678170813).
Test title is: three dimensional user input
---
Sample of claim text: 1 a digital logic circuit comprising a programmable logic device configured to include a pipeline that comprises a matching stage and a downstream extension stage the matching stage being configured t
Predicted title is: system and method for performing expression based on instruction time (with prob 9.03439755326292e-05).
Test title is: method and apparatus for performing similarity searching
---
Sample of claim text: 1 a method for deriving information from a network that is used to model web traffic data the method comprising receiving by a web traffic analysis server web traffic data that is collected by a websi
Predicted title is: method and system for determining the presence of a communication network information and method of the same (with prob 0.00038204782414073336).
Test title is: knowledge discovery from networks
---
Comments on Results
From this training there now appears more of a link between the claim text and the predicted title. The model seems to be learning a few patterns such as - "method and system for creating a [] method and system method".
This result seems close:
Sample of claim text: 1 an apparatus comprising a capacitive sense array and a processing device wherein the capacitive sense array is configured to detect a presence of a touch object or a stylus wherein the capacitive se
Predicted title is: method and apparatus for displaying a touch screen method and apparatus for the same (with prob 1.9565373226245597e-05).
Test title is: capacitive sense array for detecting touch objects and an active stylus
Training still appears unstable. Some of this may be due to the shuffling for regularisation.
The results appear an improvement though on the previous model. It is worth keeping this feature.
Options for Further Investigation
It may be worth experimenting with different training parameters and not shuffling the data. Lowering the batch size might reduce some of the loss variance.
Also adding some regularisation may help prevent overfitting. Maybe by adding some dropout (0.2?) to the LSTMs and by adding an L2 regulariser to the dense layer.
Chollet/Brownlee Model
Adapting this model is also fairly straightforward. We define the shared embedding layer as before, initialised with the GloVe weights, and use in place of our separate embedding layers from before.
from random import randint
from numpy import array
from numpy import argmax
from numpy import array_equal
from keras.utils import to_categorical
from keras.models import Model
from keras.layers import Input
from keras.layers import LSTM
from keras.layers import Dense
def target_one_hot(input_seqs, seq_max_len, vocab_len):
""" Convert a sequence of integers to a one element shifted sequence of one-hot vectors."""
one_hot_out = np.zeros((len(input_seqs), seq_max_len, vocab_len))
for i, sequence in enumerate(input_seqs):
for t, word_int in enumerate(sequence):
if t > 0:
# Shift decoder target get so it is one ahead
one_hot_out[i, t-1, word_int] = 1
return one_hot_out
# We need to convert this for our present problem - this is similar to our generate dataset above
# prepare data for the LSTM
def get_dataset(X, Y, i, i_end, num_decoder_tokens):
"""Return encoder_input_data, decoder_input_data, and decoder_target_data, latter as one-hot"""
encoder_input_data = X[i:i_end]
decoder_input_data = Y[i:i_end]
decoder_target_data = target_one_hot(decoder_input_data, Y.shape[1], num_decoder_tokens)
return encoder_input_data, decoder_input_data, decoder_target_data
# returns train, inference_encoder and inference_decoder models
def define_models(vocab_size, latent_dim, embedding_matrix):
# define training encoder
# Define an input sequence and process it.
encoder_inputs = Input(shape=(None,))
Shared_Embedding = Embedding(
output_dim=latent_dim,
input_dim=vocab_size,
weights=[embedding_matrix]
)
encoder_embedding = Shared_Embedding(encoder_inputs)
encoder_outputs, state_h, state_c = LSTM(latent_dim, return_state=True)(encoder_embedding)
encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None,))
# Possibly share the embedding below
decoder_embedding = Shared_Embedding(decoder_inputs)
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_embedding, initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# define inference encoder
encoder_model = Model(encoder_inputs, encoder_states)
# define inference decoder
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
# Need to adjust this line for the embedding
decoder_outputs, state_h, state_c = decoder_lstm(decoder_embedding, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states)
# return all models
return model, encoder_model, decoder_model
def train_model(X_train, Y_train, X_test, Y_test, model, set_size, batch_size, num_decoder_tokens):
""" Code to train model in sets of set_size."""
num_examples = len(X_train)
num_test = len(X_test)
train_loss = []
val_loss = []
# Loop here to avoid memory issues with the target one hot vector
for i in range(0, num_examples, set_size):
if i + set_size >= num_examples:
i_end = num_examples
else:
i_end = i + set_size
# Generate a range for the test data
i_test = math.floor(i * (num_test/num_examples))
i_test_end = math.floor(i_end * (num_test/num_examples))
# Generate small sets of train and test data
I_1_train, I_2_train, Y_set_train = get_dataset(X_train, Y_train, i, i_end, num_decoder_tokens)
I_1_test, I_2_test, Y_set_test = get_dataset(X_test, Y_test, i_test, i_test_end, num_decoder_tokens)
print('[INFO] Training model: {}/{} samples'.format(i, num_examples))
callback = model.fit(
[I_1_train, I_2_train],
Y_set_train,
validation_data=([I_1_test, I_2_test], Y_set_test),
batch_size= batch_size,
epochs=1
)
train_loss += callback.history['loss']
val_loss += callback.history['val_loss']
return model, train_loss, val_loss
# define model
train, infenc, infdec = define_models(vocab_size, word_embedding_size, embedding_matrix)
train.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
train.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_14 (InputLayer) (None, None) 0
__________________________________________________________________________________________________
input_13 (InputLayer) (None, None) 0
__________________________________________________________________________________________________
embedding_5 (Embedding) (None, None, 100) 250000 input_13[0][0]
input_14[0][0]
__________________________________________________________________________________________________
lstm_9 (LSTM) [(None, 100), (None, 80400 embedding_5[0][0]
__________________________________________________________________________________________________
lstm_10 (LSTM) [(None, None, 100), 80400 embedding_5[1][0]
lstm_9[0][1]
lstm_9[0][2]
__________________________________________________________________________________________________
dense_5 (Dense) (None, None, 2500) 252500 lstm_10[0][0]
==================================================================================================
Total params: 663,300
Trainable params: 663,300
Non-trainable params: 0
__________________________________________________________________________________________________
train_loss = []
val_loss = []
Y_test[0]
array([ 34, 83, 87, 3, 644, 35, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)
t_joint.word_index["startseq"], t_joint.word_index["stopseq"]
(34, 35)
# setup variables
epochs = 20
batch_size = 32
set_size = 5000
for e in range(0, epochs):
print("\n--------\n Epoch - ", e)
train, tl, vl = train_model(X_train, Y_train, X_test, Y_test, train, set_size, batch_size, num_decoder_tokens)
train_loss += tl
val_loss += vl
model.save_weights("chollet_weights_v2.hdf5", overwrite=True)
--------
Epoch - 0
[INFO] Training model: 0/20505 samples
Train on 5000 samples, validate on 1250 samples
Epoch 1/1
5000/5000 [==============================] - 77s 15ms/step - loss: 1.9163 - acc: 0.6911 - val_loss: 1.8874 - val_acc: 0.6925
[INFO] Training model: 5000/20505 samples
Train on 5000 samples, validate on 1250 samples
Epoch 1/1
5000/5000 [==============================] - 85s 17ms/step - loss: 1.8805 - acc: 0.6966 - val_loss: 1.9176 - val_acc: 0.6897
[INFO] Training model: 10000/20505 samples
Train on 5000 samples, validate on 1250 samples
Epoch 1/1
5000/5000 [==============================] - 85s 17ms/step - loss: 1.8370 - acc: 0.7020 - val_loss: 1.8404 - val_acc: 0.7031
--------
......etcetc....
--------
Epoch - 19
[INFO] Training model: 0/20505 samples
Train on 5000 samples, validate on 1250 samples
Epoch 1/1
5000/5000 [==============================] - 118s 24ms/step - loss: 1.2376 - acc: 0.7554 - val_loss: 1.5488 - val_acc: 0.7297
[INFO] Training model: 5000/20505 samples
Train on 5000 samples, validate on 1250 samples
Epoch 1/1
5000/5000 [==============================] - 116s 23ms/step - loss: 1.2313 - acc: 0.7557 - val_loss: 1.6187 - val_acc: 0.7252
[INFO] Training model: 10000/20505 samples
Train on 5000 samples, validate on 1250 samples
Epoch 1/1
5000/5000 [==============================] - 116s 23ms/step - loss: 1.2158 - acc: 0.7580 - val_loss: 1.5834 - val_acc: 0.7288
[INFO] Training model: 15000/20505 samples
Train on 5000 samples, validate on 1250 samples
Epoch 1/1
5000/5000 [==============================] - 118s 24ms/step - loss: 1.2380 - acc: 0.7529 - val_loss: 1.5333 - val_acc: 0.7379
[INFO] Training model: 20000/20505 samples
Train on 505 samples, validate on 127 samples
Epoch 1/1
505/505 [==============================] - 13s 25ms/step - loss: 1.2426 - acc: 0.7504 - val_loss: 1.7648 - val_acc: 0.6979
Again this seems to offer an improvement by lowering our loss.
# summarize history for accuracy
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Iteration')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
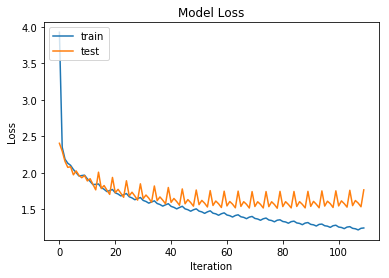
Our training and model loss end up lower and are slowly decreasing. This again suggests that the shared embedding is an improvement. We still look to plateau on our training data after 40-50 iterations (~9 or 10 epochs). From about 40 iterations we start overfitting on our training data.
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
Again we adapt this to use the word_index entries.
def predict_sequence(infenc, infdec, source, decoder_seq_length, temp=1.0):
# encode
state = infenc.predict(source)
# start of sequence input
target_seq = array([t_joint.word_index["startseq"]])
# collect predictions
output = list()
for t in range(decoder_seq_length):
# predict next char
yhat, h, c = infdec.predict([target_seq] + state)
# update state
state = [h, c]
# update target sequence - this needs to be the argmax
next_int = sample(yhat[0, 0, :], temp)
output.append(next_int)
# It seems like we throw a lot of information away here - can we build in the probabilities?
target_seq = array([next_int])
# Check for stopping character
if next_int == t_joint.word_index["stopseq"]:
break
return output
# Testing
num_test_titles = len(X_test)
indices = np.arange(num_test_titles)
np.random.shuffle(indices)
X_test = X_test[indices]
Y_test = Y_test[indices]
for i in range(0, 5):
pred_seq = predict_sequence(infenc, infdec, X_test[i], decoder_seq_length, temp=0.8)
predicted_text = seq2text(pred_seq, y_dictionary)
Y_test_text = seq2text(Y_test[i], y_dictionary)
claim_text = seq2text(X_test[i], x_dictionary)
print("Sample of claim text: {}\n".format(claim_text[0:200]))
print("Predicted title is: {}. \n Test title is: {} \n---\n".format(predicted_text, Y_test_text))
Sample of claim text: 1 an audio playback system comprising a playback engine for playing audio data according to control information playback of the audio data a snapshot module comprising a memory for saving a plurality
Predicted title is: party exclusive load sharing an iteration addition in a multi purpose computer .
Test title is: music and audio playback system
---
Sample of claim text: 1 a computer implemented method comprising receiving by a computing system a translation for content from a of the translation the content being associated with an item in an electronic providing the
Predicted title is: necessary internal hybrid point to semiconductor apparatus .
Test title is: techniques for translating content
---
Sample of claim text: 1 a display device for installation in a comprising a detector that detects a touch operation an image associated with the display device that acquires at least two of a navigation image containing ma
Predicted title is: placed microprocessor network sections size .
Test title is: display device display program and display method
---
Sample of claim text: 1 a method of using a computer to determine a of an object in a system comprising receiving from clients in the system the identifying an object detected at the clients determining a of the object on
Predicted title is: stock coverage floating strings monitored applications .
Test title is: using confidence about user in a system
---
Sample of claim text: 1 a system comprising a processor an audio content registry component executable by the processor to register an audio content item wherein the audio content item has an insertion point at which to an
Predicted title is: necessary causing computers space .
Test title is: service to audio content with targeted audio advertising to users
---
These titles still appear worse than those produced with the Ludwig model, despite a lower loss. The model almost appears to be guessing random words. This may be due to how the decoder is trained.
Summary
Here we have looked at applying pre-trained word embeddings, and a shared embedding layer, to our sequence to sequence models.
This approach appears to very slightly improve our models. At the very least, it does not appear to worsen the models and provides a useful simplification. Hence, it appears to be a useful addition to our models.
Making Things Easier
As we saw in this post, we are now reusing much of our previous code. To simplify our notebooks it would now be a good idea to abstract over some of the functionality. To do this we can create Python objects (classes) that have a common interface for both models, and that maximise reuse of common routines where possible.
To this end we can create four classes:
- An abstract class that defines the common interfaces. This is found in the file here.
- A derived abstract class that defines common sequence-to-sequence model functions. This is found in the file here.
- A concrete class for the Ludwig model with shared embeddings. This differs from the above class through the use of a custom
_build_model()function. This is found in the file here. - A concrete class for the Chollet/Brownlee model with shared embeddings. This also differs from the derived abstract class through the use of a custom
_build_model()function. This is found in the file here.
We can then concentrate on over-riding the model building part of the class while leaving all other functions the same.